# 注意
爬取热搜需要 cookie 和文件路径不然报错无法运行
# author:Naraci | |
# time:2022/5/6 10:53 | |
# WX:Naraci | |
# file: 微博热搜.py | |
# IDE:PyCharm | |
import requests | |
from bs4 import BeautifulSoup | |
from urllib import parse | |
import xlwt | |
headers = { | |
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36' | |
' (KHTML, like Gecko) Chrome/101.0.4951.41 Mobile Safari/537.36 Edg/101.0.1210.32', | |
'cookie': '填入cookie' | |
} | |
def Get_html(url): # 获取页面 | |
response = requests.get(url, headers=headers) | |
if response.status_code == 200: | |
parse_html(response.text) | |
else: | |
print(response.status_code) | |
pass | |
def parse_html(content): # 解析页面 | |
soup = BeautifulSoup(content, 'lxml') | |
tds = soup.find_all('a') | |
datalist = [] # 创建一个列表 | |
for a in tds: | |
data = [] | |
title = a.get_text() | |
URL = a['href'] | |
URL_whole = parse.urljoin('https://s.weibo.com/', URL) | |
print(title) | |
print(URL_whole) | |
print("写入完成!!!!!") | |
data.append(title) # 写入标题 | |
data.append(URL_whole) # 写入链接 | |
datalist.append(data) | |
book = xlwt.Workbook(encoding='utf-8', style_compression=0) # 生成 excel 文件 | |
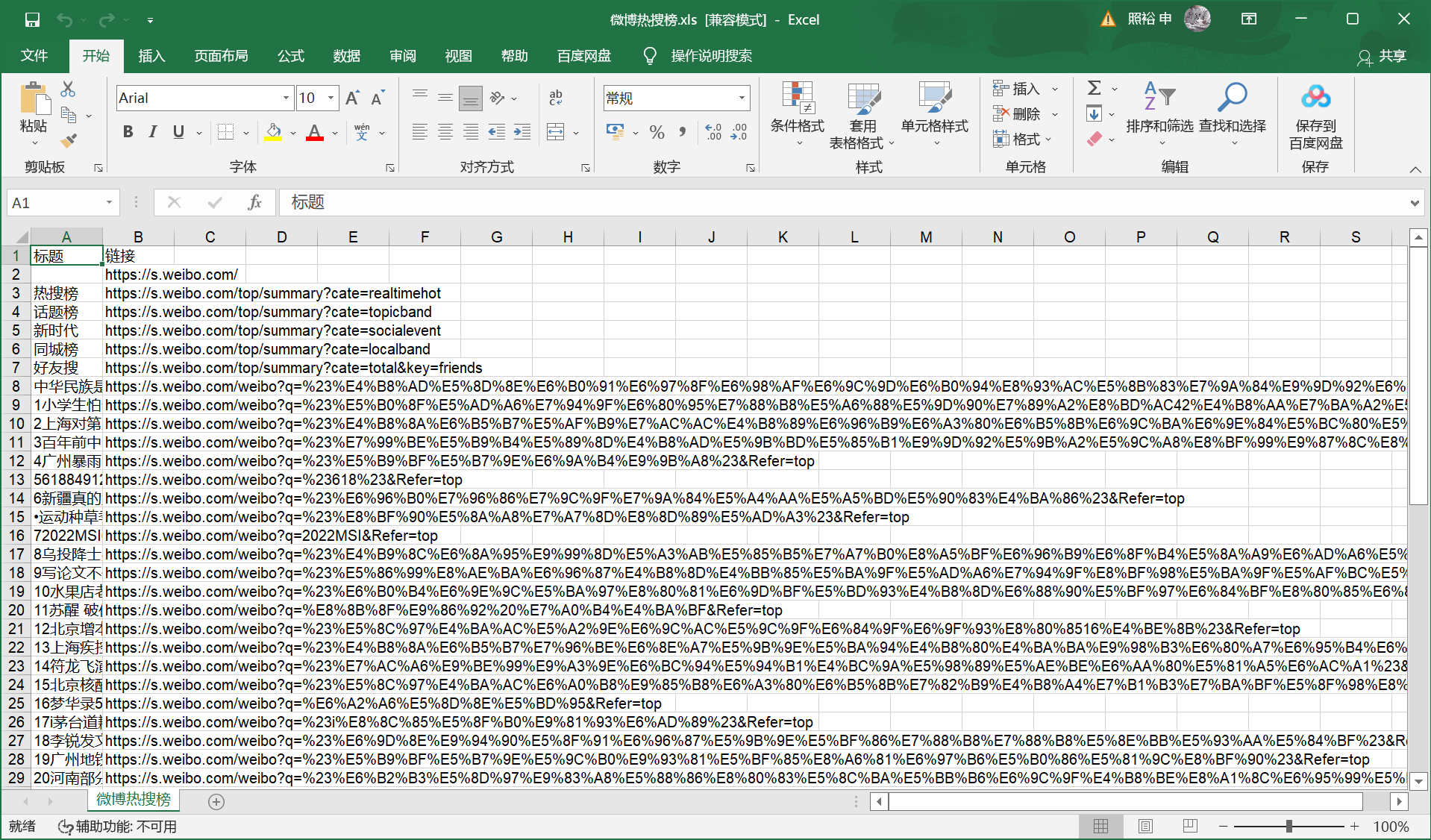
sheet = book.add_sheet('微博热搜榜', cell_overwrite_ok=True) # 生成一个表单 | |
cols = ['标题', '链接'] | |
for col in range(len(cols)): | |
sheet.write(0, col, cols[col]) | |
for i in range(len(datalist)): | |
data = datalist[i] | |
for j in range(len(data)): | |
sheet.write(i + 1, j, data[j]) | |
book.save("C:/路径/微博热搜榜.xls") | |
if __name__ == '__main__': | |
url = 'https://s.weibo.com/top/summary' | |
Get_html(url) |